概览
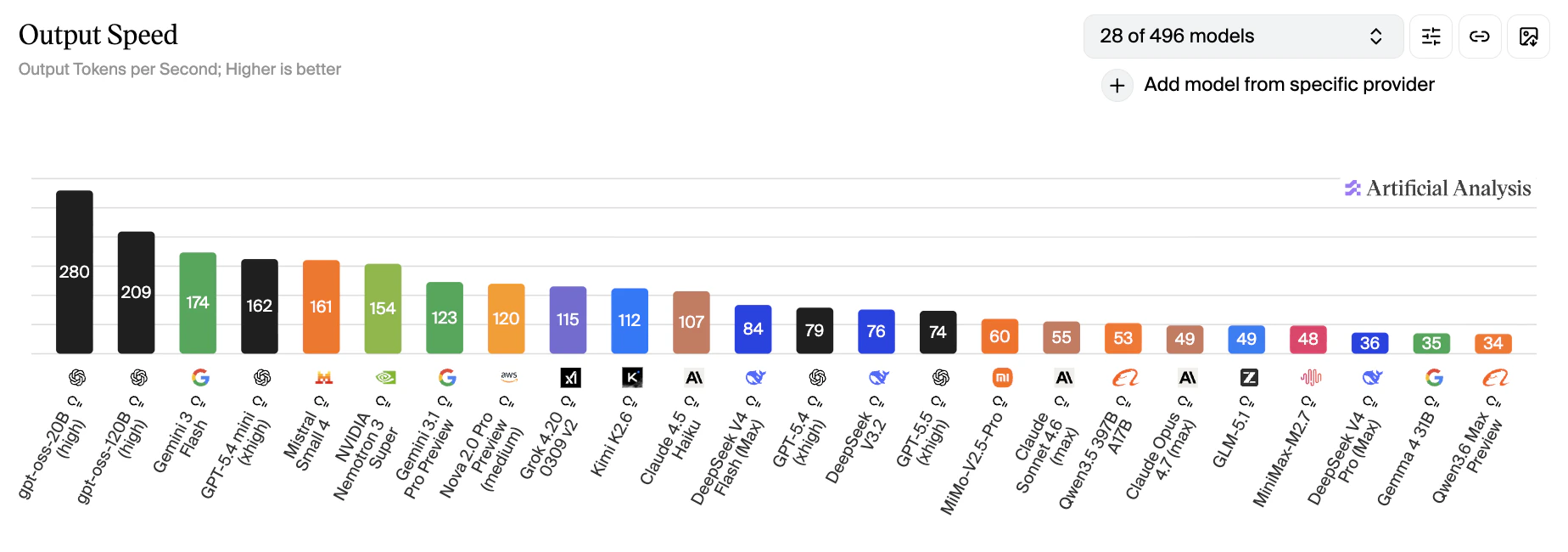
Verve AI 提供 20 个 AI 模型,初次选择可能会让人眼花缭乱。本指南会按面试类型给出实用建议——但请记住,个人偏好最重要。建议你先在 模型调试 中用真实面试题测试,找到最适合自己的模型。整体表现
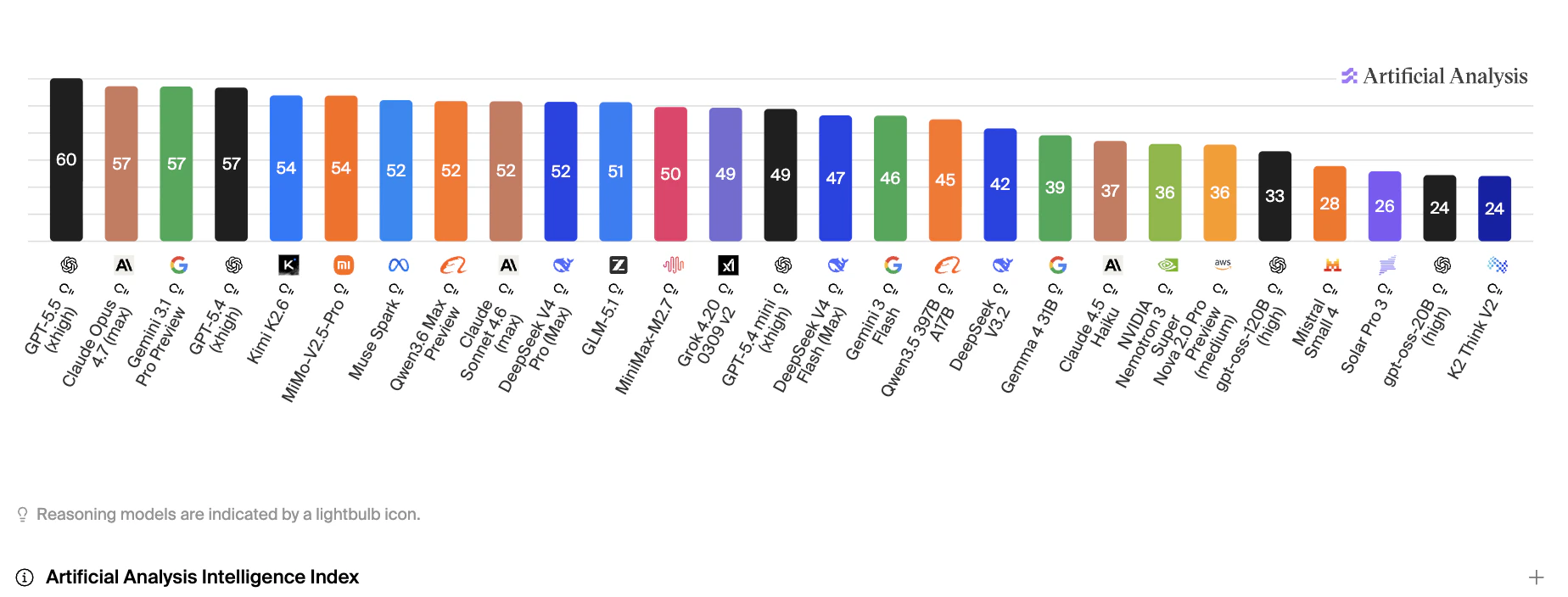
响应速度
按面试类型快速推荐
技术编码面试
推荐模型:- Claude 4.6 Sonnet - 代码解释出色,调试辅助很强
- DeepSeek V3.2 - 编码题深度推理
- DeepSeek V3.1 - 算法与数据结构能力强
- GPT-5.4 - 编码问题整体均衡
模型表现对比
从不同维度对比模型表现,以做出更合适的选择:编码能力
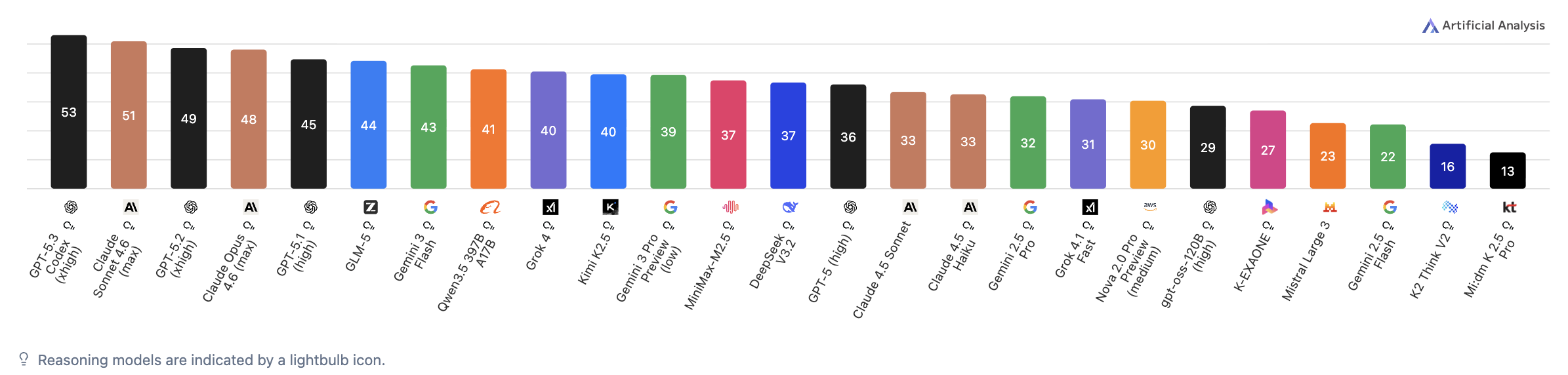
在线测评
推荐模型:- DeepSeek V3.2 - 面向 在线测评 场景的强力代码生成
- GPT-5.4-Mini - 针对限时挑战做了速度优化
- DeepSeek V3.1 - 适合复杂问题的深度推理
- GPT-5.4 - 适配多种 在线测评 形式
系统设计面试
推荐模型:- Claude 4.6 Sonnet - 架构思考与取舍分析业界领先
- Grok 4 Reasoning - 适合扩展性讨论的高级推理
- Gemini 3 Pro - 擅长多维度问题分析
- Kimi K2 Thinking - 擅长拆解复杂系统
行为面试
推荐模型:- GPT-5.4 - 更自然、更像人类的表达
- Gemini 3 Flash - 擅长组织情境任务行动结果结构的回答
- Claude 4.6 Sonnet - 更细致、思考更充分
数据科学与机器学习面试
推荐模型:- Claude 4.6 Sonnet - 统计推理与 ML 解释能力强
- Gemini 3 Pro - 数据分析能力突出
- DeepSeek V3.2 - ML 技术深度强
- MiniMax M2.5 - 适合复杂 ML 话题的长上下文推理
案例面试 咨询/商业
推荐模型:- Claude 4.6 Sonnet - 结构化解题与商业推理强
- GPT-5.4 - 分析能力更均衡
- Gemini 3 Pro - 擅长多维商业分析
- Grok 4 Reasoning - 擅长搭建逻辑框架
语言专项面试
推荐模型:- Claude 4.6 Sonnet - 多语言质量较高
- GPT-5.4 - 多语言能力强
- GLM-5 - 中文及其他亚洲语言更强
- Kimi K2.5 - 中文面试表现优秀
如何找到最适合你的模型
1
从与你面试类型匹配的推荐模型开始
根据你即将参加的面试,先用上面的推荐作为起点。
2
在模型调试用真实问题测试
前往 模型调试,用你预计会被问到的真实问题进行测试。
3
并排对比 2–3 个模型
用同一个问题测试不同模型,对比回复风格、速度与质量。
4
考虑你的个人偏好
有人喜欢简洁,有人希望解释更详细。选择最符合你表达习惯的即可。
5
测试不同回复风格
在简洁、解释型、默认等模式间切换来微调输出格式。想更深度定制,可尝试创建自定义回复风格并使用个性化提示词。
6
应用设置并进行练习验证
找到满意的组合后,应用设置并跑一场模拟面试来验证效果。
常见问题
面试中可以切换模型吗?
面试中可以切换模型吗?
不可以,面试过程中无法更换模型。请在开始面试前选定模型,并先在模型调试测试确认是否符合你的需求。
最贵/最大的模型一定最好吗?
最贵/最大的模型一定最好吗?
不一定。像 Claude 4.6 Sonnet 这类大模型擅长复杂推理,但在快速编码题里,GPT-5.4-Mini 或 Gemini 3 Flash 这类轻量模型可能更快、更实用。是否“最好”取决于你的面试类型与个人工作流。
不同面试轮次要用不同模型吗?
不同面试轮次要用不同模型吗?
建议这么做。技术轮用更偏编码的模型;系统设计用更偏推理与架构的模型;行为面试用更偏对话表达的模型。每种场景都建议先在模型调试测试。
如果是混合面试 编码 + 系统设计 怎么办?
如果是混合面试 编码 + 系统设计 怎么办?
可以先用更通用的高阶模型,例如 Claude 4.6 Sonnet 或 GPT-5.4,它们兼顾编码与高层推理。注意:面试中无法切换模型,如需更换请在开场前决定。
如何判断模型是否适合我?
如何判断模型是否适合我?
你可以自问:
- 回复速度是否匹配我的面试节奏?
- 解释是否自然、好理解?
- 技术准确度是否足够高?
- 语气是否像我自己会说的话?
高性价比/轻量模型能用于真实面试吗?
高性价比/轻量模型能用于真实面试吗?
可以。像 GPT-5.4-Mini、Gemini 3 Flash 这类模型速度快、能力也不错,适合连珠炮式提问或“速度比深度更重要”的面试。建议先测试,确保质量满足你的要求。